
Service Fabric on Azure Cluster
在介绍一个 Service Fabric 项目是如何在 Azure Cluster 上跑起来之前,我们需要先了解下 Azure 上的一些 PaaS。
- Public IP Address:对一个 domain name 提供 IP 解析。可与一组 VM Scale Set 绑定,
- Load Balancer:负载均衡器。先分别配置前端 IP 和后端 backend pools;并手动配置负载均衡规则——将前端 IP 映射到后端单个 pool,一个 pool 可能是单个 vm,也可能是一个 vm 集群;每个规则均可以配置 Health Probe 进行检查。此外,还可以主动进行 NAT / PAT。(比如项目中可用于直接转发 RDP 流量。)
- Virtual Net:定义虚拟网络的范围,可为 Virtual Machine Scale Set 中的每一个实例 instance / device 分配 private IP address。
- Netwwork Security Group:网关,可分别配置 Inbound 和 Outbound 的流量规则。对 Inbound Source 可指定具体的 IP Address Range,也可以是 Service Tag。(Service Tag 本质是上一组预先定义好的identifiers,代表着一类 IP 地址。比如 Tag
VirtualNetwork代表所有的虚拟/本地网络地址空间、TagAzure Load Balancer代表 Azure Load Balancer 进行 health probe 时的源 IP 地址。) - Virtual Machine Scale Set / Node Type:一个集群上的一组 vm 实例,该 Cluster 中的所有 node / vm 都具有相同的大小和特征,如 CPU 数量、内存、磁盘数量、IO 等。可以为每一种 Node Type 分别进行扩展,比如修改 OS SKU、打开不同的端口。(但是一种 Node Type 中的所有 instance 都一样。)网关使用 Network Security Group,负载均衡使用 Load Balancer。
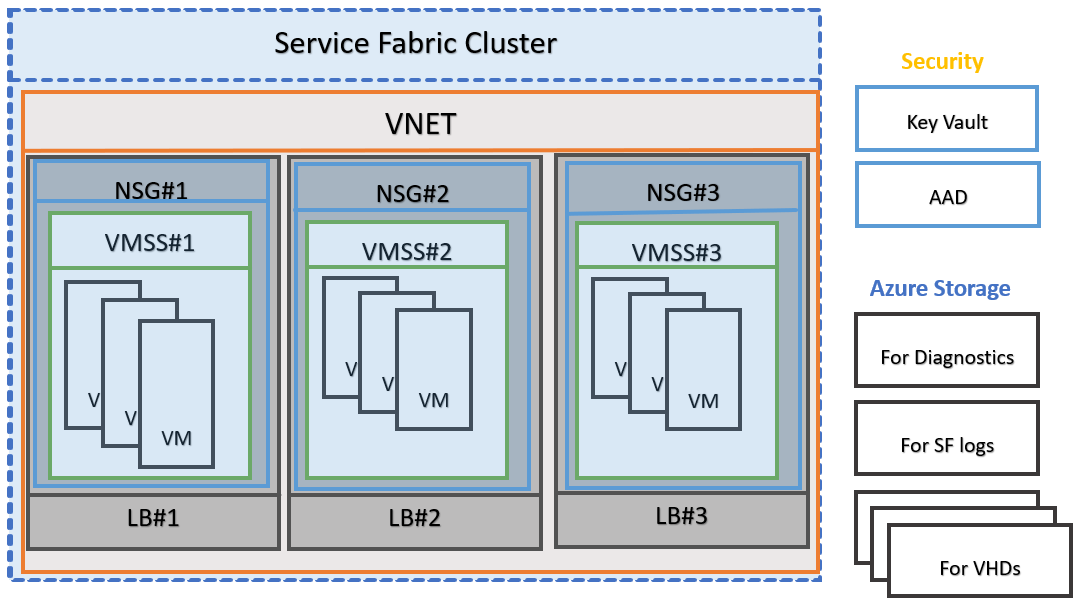
上图所示的是 Azure Cluster 上 Service Fabric 项目的架构(详见文档)。每一组 VMSS / Node Type 都有着独立的 Load Balancer 和网关 NSG。所以当外部流量通过域名访问时,该域名会先被 Public IP Address 转换为对应的 IP 地址,然后经过 NSG 网关拦截过滤,到达 Load Balancer 流量转发,从而击中具体节点。
但是 Load Balancer 是映射到后端的一个 pool 中,其中可能是一个包含多个实例的 VMSS,那么 Load Balancer 怎么知道将流量转发给 pool 中具体哪个节点呢?且因为 Service Fabric Cluster 对服务进行了服务编排、负载均衡(可参考之前的文章),目标服务可能只在某些节点上存在,所以随意转发肯定是不行的。
Service Communication
在文档中只描述了 Service Fabric 部署到 Azure 上的情况(当然要支持自家产品啦🐽 make sense),而且据文档所言,个人认为 Service Fabric 与 Azure Load Balancer 有着比较强的耦合,Azure Load Balancer 实际做了对 Service Fabric Cluster 中每个 Service Instance 的服务发现,而不是由 Service Fabric 自己来实现的。所以如果直接迁移到别的云平台上,不一定能正常 work。
FYI:Service Fabric 在启动一个 Service 的实例时,如果该 Service 使用了某个特定端口,Service Fabric 会在 vm 上帮你打开这个端口。👏🏻
外部到达 Cluster 的所有流量都必须通过 Azure Load Balancer(从架构图中也可以看出来),如果某个入站流量需要访问端口 port,它将自动转发该流量到某个随机的节点上,而这个随机节点上此端口 port 是打开的。Azure Load Balancer 仅知道节点上的端口是打开的,但不知道这个端口是被具体哪个 Service 打开的。
具体来说,Azure Load Balancer 会使用探针 probe 来确定是否将流量导向某个特定节点,探针 probe 会周期性地检查每个节点上的相关端点,以确定该节点是否可以响应。如果探针 probe 在尝试一定次数(可配置)后失败了,Azure Load Balancer 就会停止向该节点转发流量。通过 Azure Portal 创建一个集群时,会自动为配置的每个自定义端口设置一个探针 probe。
在实际中,我们所有的路由规则都有对应的探针 probe。

对探针 probe 可配置其探测协议、探测端口、间隔时间、确定为 unhealthy 状态的阈值(即连续探测失败次数)。
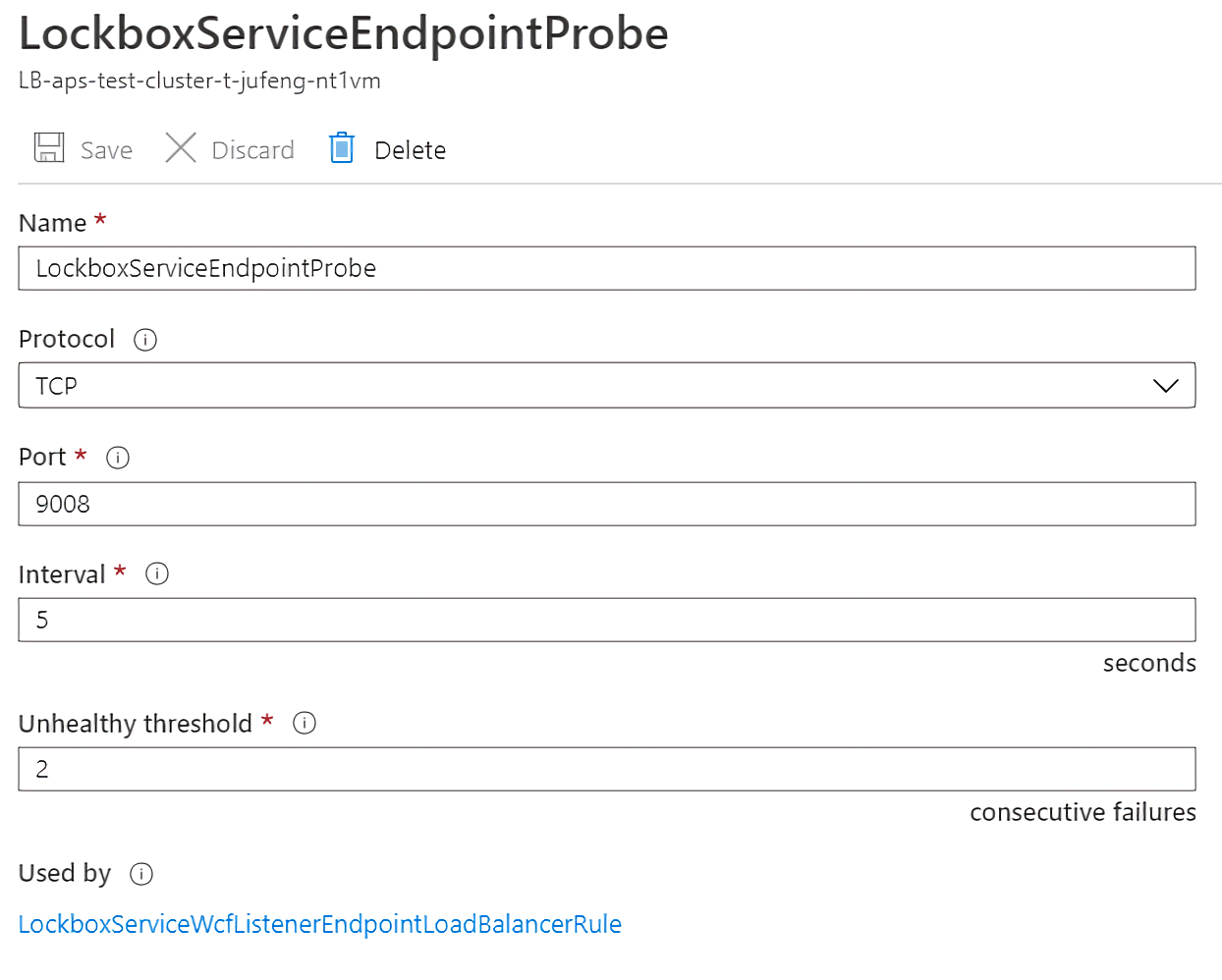
注意:Azure Load Balancer 和探针 probe 仅仅知道节点 nodes,而不知道在 nodes 上运行的 services。Azure Load Balancer 将总是向响应探针 probe 的节点转发流量,所以必须小心确保在这些响应探针 probe 的节点上有相关的可用服务 Service。
Service Fabric 框架提供了几种 pre-built 的通信选项(不指明协议、HTTP、WCF),但是选择哪种来使用取决于编程模型的选择、通信框架以及编写 Service 的编程语言。
此外,各个服务间可以使用任何协议或框架进行通信,无论其是基于 TCP 套接字的自定义二进制协议,还是通过 Azure Event Hub 或 Azure IoT Hub 的流事件(streaming events)。Service Fabric 提供了相关通信的 API,用户可以将其插入通信堆栈(Communication Stack),与此同时,服务发现和连接等的所有工作都由框架实现,对用户屏蔽。有关更多详细信息,请参见有关可靠服务通信模型的文章。具体实现可参考官方文档。
与服务编排相区分
| 服务发现 | 服务编排 | |
|---|---|---|
| 概念 | 转发外部流量到具体节点时需要知道哪些节点上有此相关服务 | 对集群中各个节点上的服务进行编排、负载均衡,保证各节点不过忙也不过闲,确保有效利用群集中的资源 |
| 主体 | Azure Load Balancer | Cluster Resource Manager |
| 实现 | 探针 probe 检测相应端口 | 收集各个 node 上 Local Node Agent 的信息并聚合在一起得到全局的状态信息,以确定是否需要做出什么操作来 balance |
Load Balancing in gRPC
在单纯的 gRPC 项目中,Client 与 Server 端交互有着自己的一套逻辑。
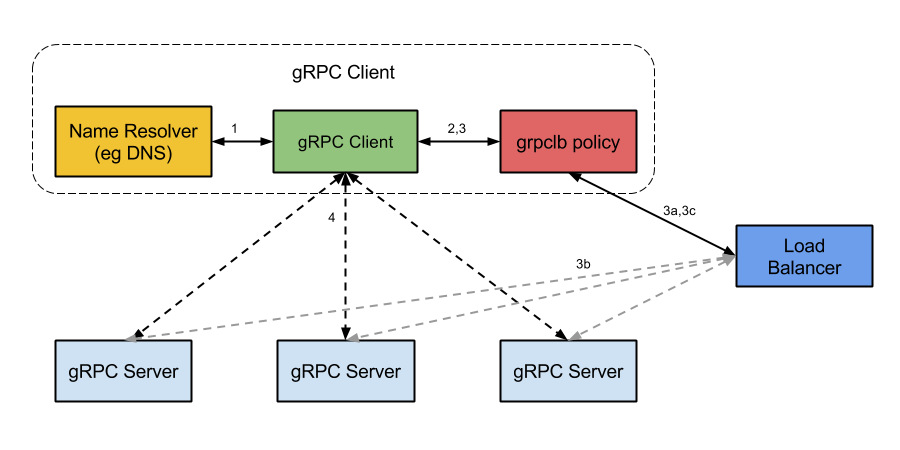
- 在启动时,gRPC Client 会针对 Server 的 domain name 发 name resolution 的请求,这可能返回多个 IP 地址和 Server 端的 service config 文件(用于指导 Client 进行负载均衡)。
- Client 初始化负载均衡策略。
- 如果 resolver 返回的地址中有 balancer 地址,Client 就会直接使用
grpclb策略,不管 service config 文件中配置的负载均衡策略是什么。 - 否则,Client 使用 service config 文件中配置的负载均衡策略。如果 service config 文件中没有配置负载均衡策略,Client 将默认使用第一个可用的 Server 地址。
- 如果 resolver 返回的地址中有 balancer 地址,Client 就会直接使用
- 负载均衡策略对每一个 Server 地址均创建一个 subchannel。
- 对除
grpclb的所有策略,对 resolver 返回的每个地址都会有一个 subchannel。注意这些策略会忽略 resolver 返回的任何 balancer 地址。 - 对
grpclb策略,工作流如下:- 在 resolver 返回的所有 balancer 地址中选一个使用,它会询问 balancer 对于之前这个 server name 应该使用哪个 server address。(注意:非 balancer 的地址会被用作 fallback 回退,以防止在策略启动之后却没有 balancer 可以被 contact 到。
- 可以配置 load balancers 使其记录每次将 Client 转发至哪一个 Server 的信息。
- Load balancer 返回一个 Server 列表给 gRPC Client 的
grpclb策略,grpclb策略会为列表中的每一个 Server 都创建 subchannel。
- 对除
- 对每一次发出的 RPC,负载均衡策略决定了该 RPC 应该被发送至哪个 subchannel (即哪个 Server)。
- 对
grpclb策略,Client 发送 RPC 请求的顺序由他们从 load balancer 返回的顺序决定。如果 Server 列表为空,该次请求会 block 住直至获得一个非空的。
- 对
Service Fabric 集成 gRPC
需求
项目 APS 中包含多个 Service,其中 LockboxMonitor 是一个 Stateless Service,它会监听一个 EventHub,并从中取出消息进行处理。此外,LockboxMonitor 启动了一个 WCF Server。鉴于 WCF 吞吐量不高且技术栈有些老旧,所以考虑替换方案 gRPC。
gRPC 在 C# 环境中的两个版本
gRPC 在 C# 环境中有两个版本,区别如下。
| grpc | grpc-dotnet | |
|---|---|---|
| 实现方式 | C# API over native C-core binaries | C# implemented gRPC |
| 使用环境 | .Net Core,.Net Framework 4.5+ | .Net Core |
| Cert | pem | pfx |
| 与 Protobuf 的集成 | 手动编译 proto 文件 | 自动编译 proto 文件 |
因为项目中使用的是 .Net Framework,所以考虑使用 C-core 版本的 grpc。
实现历程
在实现的真实历程中,我并不是一开始就了解了本文的全部上述内容,所以在逐渐深入的途中经历了几次反反复复🤧。但是这个过程其实也挺有趣👺的,所以记录一下。如果想直接了解最后的实现,可直接跳到最后。
Version 1: 直接实现
此时只是简单看了下 gRPC 的官方文档的 demo 和微软其他团队使用的 demo,直接 Server.Start() 就完事。
Version 2: 在集群中不能正常工作
此时想到了部署到 Service Fabric 的集群上的场景,但是并不知道集群上的整体架构(即还不知道有 Azure Load Balancer),更不用说 Azure Load Balancer 对 Service Fabric Cluster 进行服务发现了。
所以在这个时候我怀疑 gRPC Client 在做 gRPC 的 load balance 时是否可以正确拿到 gRPC Server 的 IP 地址。我本以为 Service Fabric 自己会做服务发现与注册这件事情,所以在想 Service Fabric 如果对外只暴露了一个 IP,那么 gRPC Client 将请求发给 Service Fabric,Service Fabric 又怎么知道将这个请求发给具体哪个实例呢?如果暴露了集群中全部实例,那么 gRPC Client 可以正常发现 gRPC Server。
然后通过 DNS 检测工具,发现只有一条 A Record,所以这时认为 Service Fabric 与 gRPC 不能集成在一起工作。
Version 3: 只能通过实现接口 ICommunicationListener 来运行
这时已经知晓了上文的全部知识点。所以发现 Version 2 的考虑就是 bullshit。🤗
上文中有提到 Service Fabric 中各个服务间可以使用任何协议或框架进行通信,只需要实现相关的接口 [ICommunicationListener](https://docs.microsoft.com/en-us/dotnet/api/microsoft.Service Fabric.services.communication.runtime.icommunicationlistener?view=azure-dotnet)。而在原来的 WCF 版本中,Service Fabric 提供了 pre-built WCF SDK,所以直接使用了官方实现的 [WcfCommunicationListener<TServiceContract>](https://docs.microsoft.com/en-us/dotnet/api/microsoft.Service Fabric.services.communication.wcf.runtime.wcfcommunicationlistener-1?view=azure-dotnet),整体就都是按照 Service Fabric 规范来的。监听 WCF 的工作是 LockboxMonitor 运行实例的一部分,且会随着该实例被正常管理、启动和删除。
但是直接启动 gRPC Server 的情况就不一样了。Server.Start() 会启动一个 gRPC 的进程,那么运行节点上的 LockboxMonitor 实例被删除后,父进程被 kill,而该 gRPC 进程有以下两种情况。
- 该 gRPC 进程会成为孤儿线程并继续运行。注意:因为 gRPC Server 中使用了 LockboxMonitor 的资源,LockboxMonitor 父进程在退出后,子进程应该仍保留有一份该资源的拷贝,所以 gRPC Server 子进程在父进程退出后仍可正常运行。
- 父进程退出前住主动回收了该 gRPC 进程。
个人感觉大概率第一种,所以就按照第一种的思路继续思考了,不过并没有做实验验证。~~希望有一天会把这个坑填上。~~😰
如果 gRPC 进程在 LockboxMonitor 进程退出后仍在运行,成为了孤儿进程,那么每个运行过 LockboxMonitor 的节点上都将存在 gRPC Server 进程,Azure Load Balancer 在对此 gRPC 端口发出探针 probe 探测时,这些节点都将响应,但是因为 Service Fabric Cluster Resource Manager 并不能对 gRPC Servers 进行管理,所以不能保证 Azure Load Balancer 探测后响应节点上有真实可运行的 gRPC Server。
所以,正确的姿势应该遵循文档,通过 gRPC 实现接口 ICommunicationListener 得到一个 GrpcCommunicationListener,使其由由 Service Fabric 进行管理。但是考虑到工作量太大🥶,所以考虑更换方案——直接通过 Event Hub 进行交流。
Version 4: 可以直接启动 Server
这是与 @XinNi 交流后的版本。因为刚接触 C# 平台,对底层其实并不了解,只是根据 Java Boy 的直觉,认为没有 JVM ➕ 之前 C / C++ 的编程经历都是多进程,所以直接先入为主认为 C# 环境下 Server.Start() 也是多进程。但是事实并不是这样。
首先,我们知道,Service Fabric Cluster 运行时在每个节点上都启动了一个 Local Node Agent 监视该节点上的 Services,且各 Service 启动时都是一个进程。(在 ServiceManifest.xml 文件中指明了 EntryPoint 的 exe 文件,该文件在 vm 节点上是可以直接双击运行的。Service Fabric Cluster Recourse Manager 做的相当于是帮用户双击 exe 文件、删除该进程、并保持 Service 实例数量满足需求即可。)
其次,.Net 平台下提供的公共语言运行库(CLR)是与 JVM 类似的抽象,所以在 Service LockboxMonitor 进程中直接使用 Server.Start() 启动的 gRPC Server 不是另一个进程而是线程,那么在 LockboxMonitor 进程被 Recourse Manager 管理、删除时,gRPC 线程自然就会退出,所以不会有上面 Version 3 的问题。
Final Data Flow
最后,让我们将整个流程串起来想一想。
- gRPC:因为 gRPC 在域名解析时只会得到 Azure Load Balancer 对外暴露的一个 Public IP Address,所以 gRPC Client 将认为 gRPC Server 只有一个,在进行 gRPC Server Health Checking 发出探针时也总是发给 Azure Load Balancer,所有流量都将转发给 Azure Load Balancer。
- Azure Load Balancer:通过探针 probe 检查内部 Service 暴露端口的状态,并在流量到达之后,转发给随机一个响应的 Service 实例。
- Service Fabric:Cluster Resource Manager 对各 Service 进行状态管理和负载均衡,在启动 LockboxMonitor 实例的进程时将起一个新的 gRPC Server 线程,删除 LockboxMonitor 实例的进程时也将导致该 gRPC Server 线程被 terminate。
所以,理论上看起来没有问题。但是以上都是基于理论分析,还没有真正做过实验,期待填坑的一天。👻
PS. 至于需求?没做实验当然不敢将修改直接上线。💩而且实习期快结束惹,估计最终还是采用简单的 Event Hub 叭。