前言
因为在部署 Service Fabric 项目到集群上时是一个分布式服务,各个节点上可能运行着多个高可用实例或副本。而在这种环境下,对各台机器进行单独配置是不现实的,所以业界提出了服务编排调度器 Orchestrator 的概念,由它来帮助管理这些环境。比如我们可以告诉 Orchestrator 「我希望在我的环境中运行此服务的五个副本」,那么 Orchestrator 就会尽可能保证环境满足此需求,不管发生什么。
当机器发生故障或工作负载由于某些意外原因而终止时,Orchestrator 会采取行动。大多数 Orchestrator 所做的不仅仅是处理失败,还包括管理新部署、处理升级以及处理资源消耗和治理等。**从根本上讲,所有 Orchestrator 都在保持环境中某些所需的配置状态。**您希望能够告诉协调器您想要什么,并让它完成繁重的工作。
典型的 Orchestrator 包括 Docker Datacenter / Docker Swarm,Kubernetes 和 Service Fabric。
Service Fabric Cluster Resource Manager
Service Fabric 中处理服务编排的系统组件为 Cluster Resource Manager,它是在为 Application 中的 Service 进行负载均衡。
传统 Load Balancer
在传统的分层应用中,往往最外层有一个 Load Balancer。有些负载平衡器是基于硬件的,例如 F5 的 BigIP 产品,而另一些负载平衡器是基于软件的,例如 Microsoft 的 NLB。在其他环境中,还有诸如 HAProxy、Nginx、Istio 或 Envoy 等。在这种体系结构中。Load Balancer 的工作是确保无状态的工作负载接收(大致)相同数量的工作。
平衡负载的策略各不相同。一些平衡器会将每个不同的请求发送到不同的服务器。而有的会提供 session pinning / stickiness 的功能,保证同一会话时总是击中同一节点。更高级的平衡器则使用对实际负载的估计 estimation 或报告 report 来根据请求的预期成本和当前机器负载来进行路由。
Cluster Resource Manager 的 Load Balance
传统的 Load Balancer 通过在前端分散流量来确保均衡,将网络流量转向 Service 已经存在的地方,即使现有的位置对于运行服务并不理想;Service Fabric Cluster Resource Manager 则会将 Service 移到 Service 最适用且流量或负载应跟随的位置。
它会将 Service 移动到最有意义的地方,期望流量随之而来。例如,它可能会将 Service 移至当前 cold 的节点,因为当前那里服务执行的工作不多,该节点 cold 的原因可能是之前存在的服务已删除或移动到了其他地方。 另一个例子,Cluster Resource Manager 还可能主动将某些 Service 移到别处,比如在机器即将进行升级时、或者由于其上运行的服务消耗激增而导致过载时、或者 Service 的资源需求可能已经增加导致这台机器上没有足够的资源来继续运行它时。
Service Fabric Cluster Resource Manager 采用了与传统 LoadBalance 根本不同的策略来确保有效利用群集中的资源。
Cluster Resource Manager 的架构
Cluster Resource Manager 必须跟踪每个 Service 的 requirements 及单个 Service Object / Instance 消耗的资源。它包含两个概念:
- Local Node Agent:运行在单个节点上,它会跟踪单个 Service 的资源消耗、变更等信息,并进行汇总,然后周期性向 Resource Manager 进行报告。Resource Manager 在得到这些信息后,会再次聚合、分析、存储,并最终根据其当前配置做出反应。💪🏻
- 容错服务。
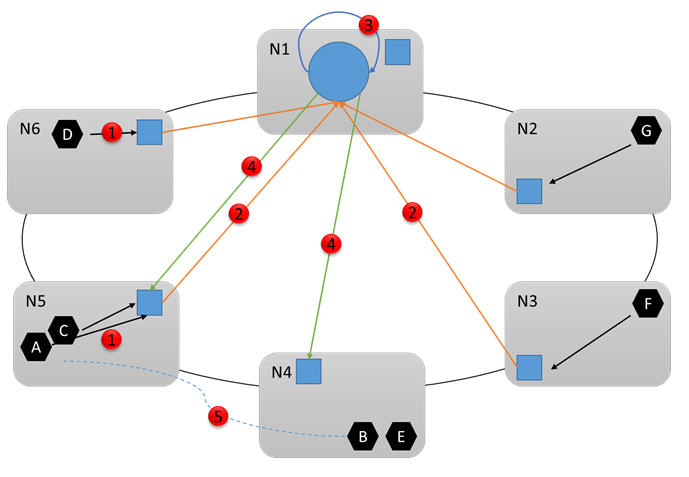
如下图所示,蓝色方块为 Local Node Agent,蓝色圆为 Resource Manager,黑色六边形为各 Service 实例,红色表示运行时的操作。
- Local Node Agent 收集该 node 上的信息。
- Local Node Agent 聚合信息并发送给 Resource Manager。
- Resource Manager 聚合、分析、存储所有信息。
- Resource Manager 根据当前配置下发命令,进行 reconfiguration。
- N5 超载,所以将服务 B 移到 N4。