
1. Introduction
GraphQL 是新的 API 标准,它提供了更有效、更强大和更灵活的对 REST 的替代方法。它由 Facebook 开发和开源,现在由来自世界各地的大型公司和个人社区维护。
GraphQL 的核心是启用声明式数据获取,客户端可以在其中确切指定从 API 中需要什么数据。GraphQL 服务器不是公开返回固定数据结构的多个端点(原文 endpoint,是指服务器端暴露出的接口,如 /users/<id>),而是仅公开一个端点,并精确地响应客户端请求的数据。
1.1 GraphQL - A Query Language for APIs
如今,大多数应用程序都需要从服务器上获取数据,而该服务器将数据存储在数据库中。API 的职责是为存储的数据提供适合应用程序需求的接口。
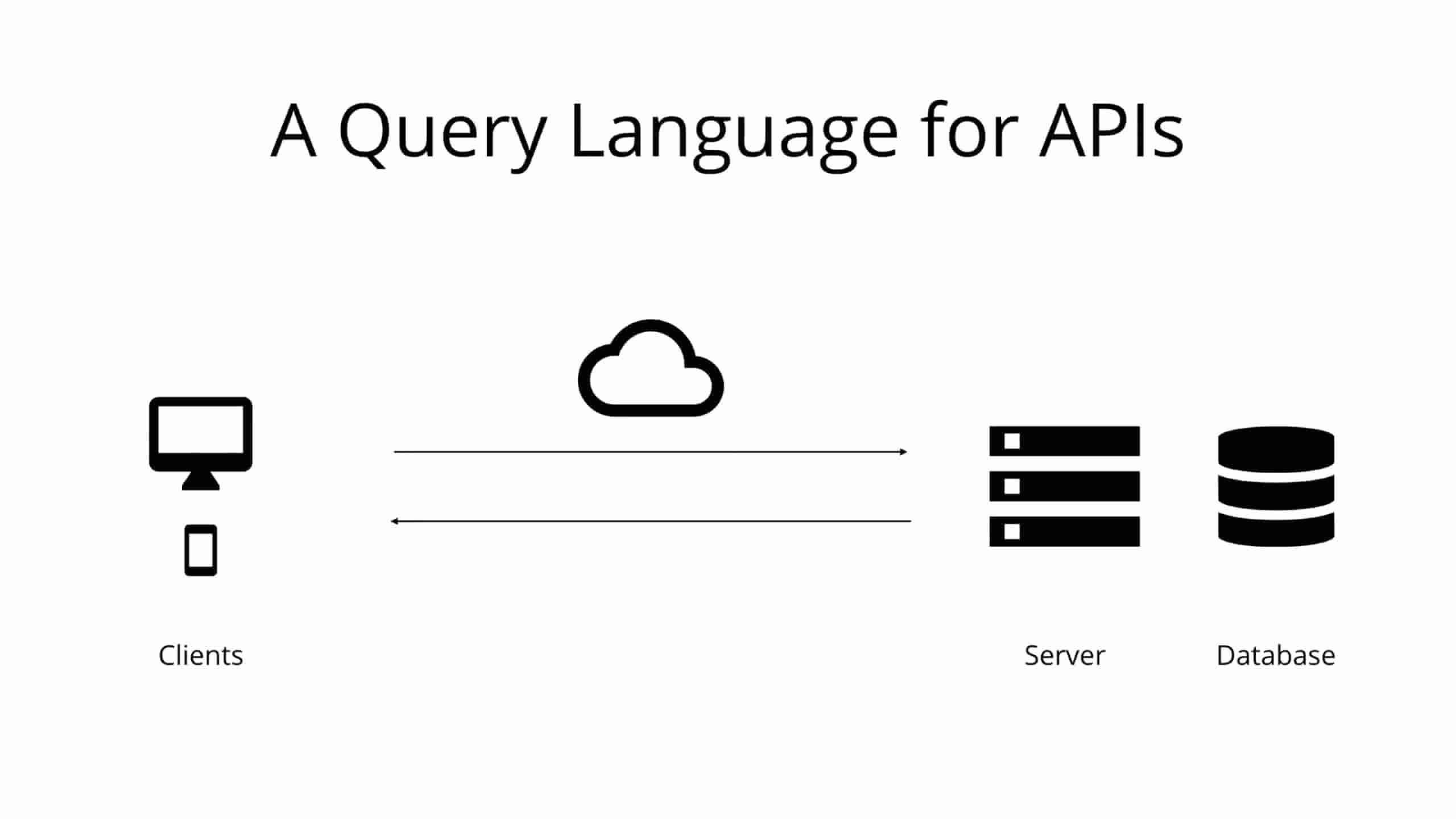
GraphQL 通常与作为数据库技术相混淆。这是一个误解,GraphQL 是 API 的查询语言,而非数据库的。从这个意义上讲,它与数据库无关,可以在使用 API 的任何情况下有效使用。
1.2 A more efficient Alternative to REST
REST 是一种从服务器暴露数据的流行方法。开发 REST 的概念时,客户端应用程序相对简单,并且开发速度不像今天这样。因此,REST 非常适合许多应用程序。但是,在过去的几年中,API 格局发生了根本性的变化。特别是以下三个因素一直在挑战 API 的设计方式:
1.2.1 移动使用量的增加导致有效数据加载的需求
移动使用的增加,低功耗设备和脆弱的网络是 Facebook 开发 GraphQL 的最初原因。GraphQL 最大限度地减少了需要通过网络传输的数据量,从而极大地改善了在这些条件下运行的应用程序。
1.2.2 各种不同的前端框架和平台
运行客户端应用程序的前端框架和平台的异构环境使得难以构建和维护一个可以满足所有需求的 API。借助 GraphQL,每个客户端都可以精确访问其所需的数据。
1.2.3 快速开发和对快速功能开发的期望
持续部署已成为许多公司的标准,快速迭代和频繁的产品更新是必不可少的。在使用 REST API 时,服务器公开数据的方式通常需要根据客户端特定需求和设计的改变而进行相应修改,以进行适配。这阻碍了快速的开发实践和产品迭代。
1.3 History, Context & Adoption
1.3.1 GraphQL is not only for React Developers
Facebook 于 2012 年开始在其移动应用程序中使用 GraphQL。但是,有趣的是,GraphQL 大多被选择用于 Web 技术的上下文,并且在移动应用程序中只获得了很小的吸引力。
Facebook 第一次在 React.js Conf 2015 上公开谈论 GraphQL,不久之后宣布了开源计划。因为 Facebook 总是在 React 的背景下谈论 GraphQL,所以非 React 开发人员花了一段时间才了解到 GraphQL 绝不是仅限于与 React 一起使用的技术。
1.3.2 A rapidly growing Community
实际上,GraphQL 是一项可以在客户端与 API 通信的任何地方使用的技术。有趣的是,像 Netflix 或 Coursera 这样的其他公司也在研究类似的想法,以提高 API 交互的效率。Coursera 设想了一种类似的技术,可以让客户指定其数据要求,而 Netflix 甚至开源了其解决方案 Falcor。在 GraphQL 开源之后,Coursera 完全取消了自己的工作,开始使用 GraphQL。如今,GraphQL 已被 GitHub、Twitter、Yelp 和 Shopify 等许多不同的公司用于生产中。
2. GraphQL is the better REST
在过去的十年中,REST 已逐渐成为设计 Web API 的标准。它提供了一些很棒的想法,例如无状态服务器和对资源的结构化访问。但是,REST API 过于灵活而无法满足访问它们的客户端的快速变化的需求。开发 GraphQL 是为了满足对更大灵活性和效率的需求! 它解决了开发人员与 REST API 交互时遇到的许多缺点和低效率。
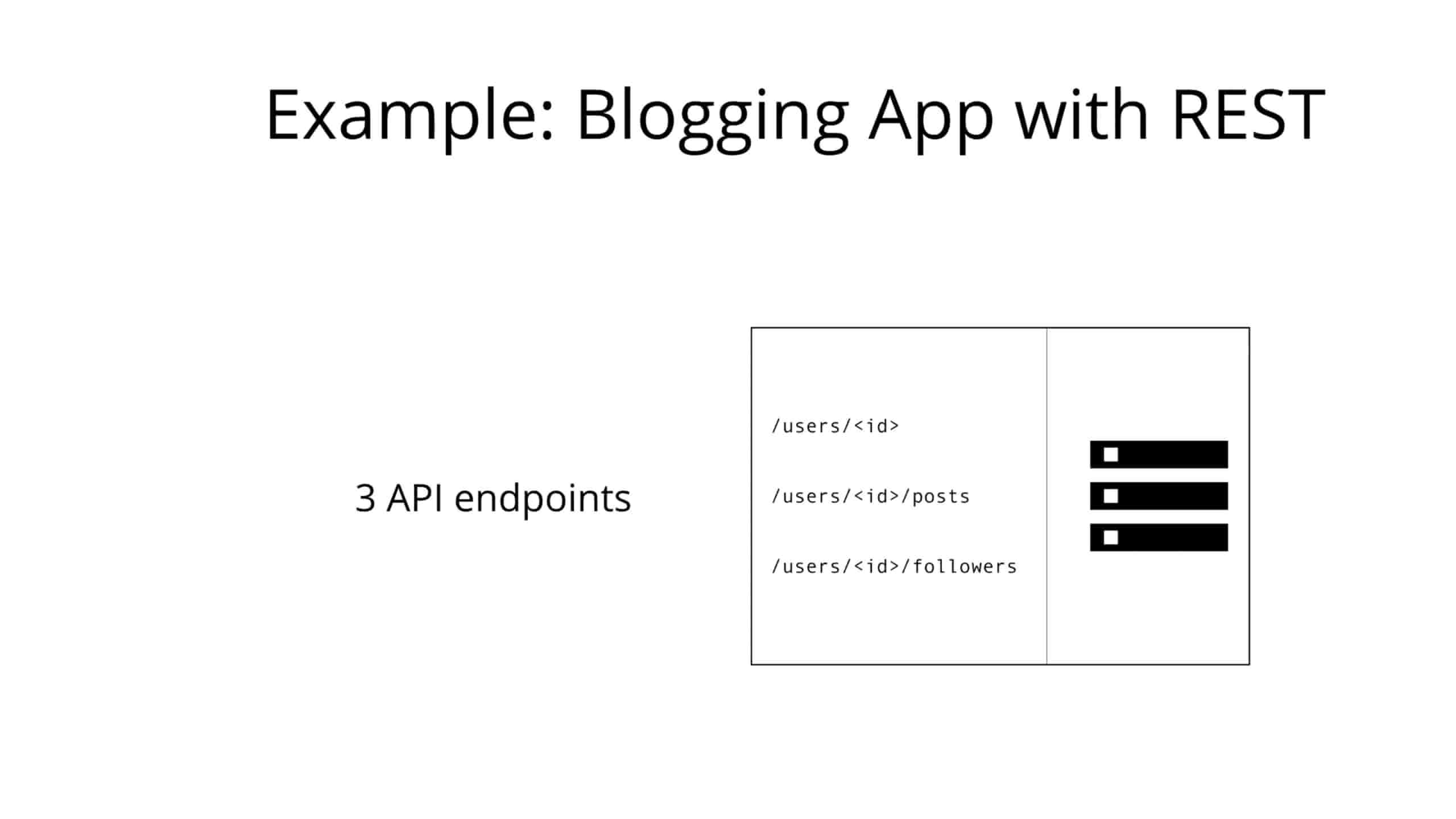
为了说明从 API 提取数据时 REST 和 GraphQL 之间的主要区别,让我们考虑一个简单的示例场景:在博客应用程序中,应用程序需要显示特定用户的帖子标题。在同一屏幕上还显示该用户的最后 3 个关注者的名称。REST 和 GraphQL 如何解决这种情况?
2.1 Data Fetching with REST vs GraphQL
使用 REST API,通常可以通过访问多个端点来收集数据。在示例中,这些可以是 /users/<id> 端点,以获取初始用户数据。其次,可能有一个 /users/<id>/posts 端点,该端点返回用户的所有帖子。然后,第三个端点将是 /users/<id>/followers,它返回每个用户的关注者列表。
而 GraphQL 中,您只需将包含具体数据要求的单个查询发送到 GraphQL 服务器。然后,服务器将使用满足这些要求的 JSON 对象进行响应。
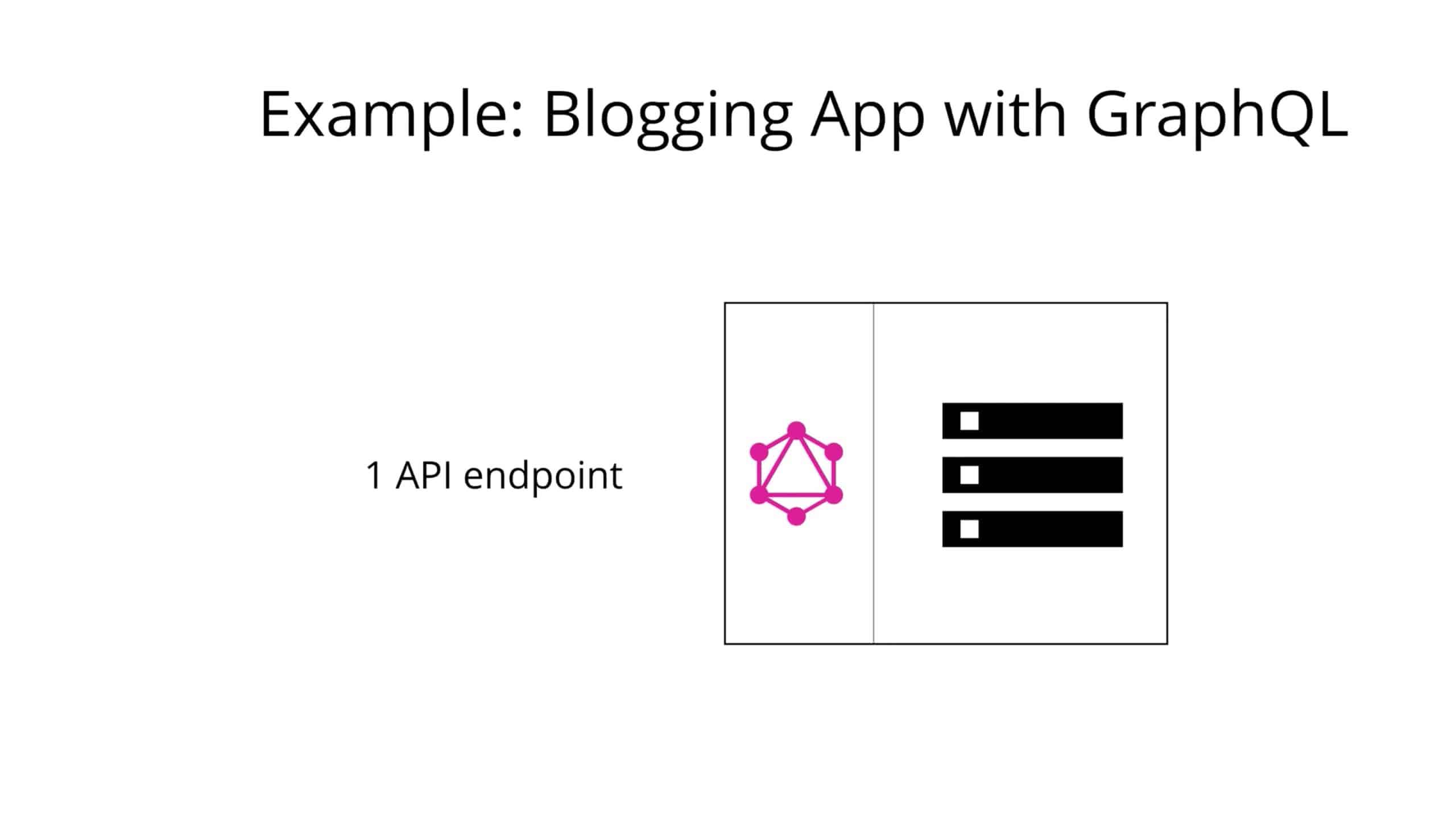
2.2 No more Over- and Underfetching
REST 最常见的问题之一是「过度获取」和「获取不足」。发生这种情况的原因是因为客户端从服务器获取数据的唯一方法是通过端点,而这些端点只会返回固定数据结构。按照能够为客户端提供准确、确切的数据需求的方式来设计 API 是非常困难的。
2.2.1 Overfetching: Downloading superfluous data
「过度获取」意味着客户端获取的信息比应用程序中实际需要的信息更多。例如,假设有一个屏幕仅需要显示带有用户名的用户列表。在 REST API 中,此应用通常会命中 /users 端点并接收带有用户数据的 JSON 数组。但是,此响应可能包含有关返回的用户的更多信息,例如他们的生日或地址,而这些对当前客户端无用,因为它只需要显示用户名即可。
2.2.2 Underfetching and the n+1 problem
另一个问题是「获取不足」和 n+1 请求问题。「获取不足」通常意味着某个特定端点无法提供足够的必需信息。客户端将不得不提出其他请求以获取其所需的一切。这可能会恶化为客户端需要首先下载元素列表,但随后需要为每个元素提出一个额外请求以获取所需数据的情况(即 n+1 问题)。
例如,考虑同一应用程序还需要显示每个用户的最后三个关注者。该 API 提供了其他端点 /users/<user-id>/followers。为了能够显示所需的信息,应用程序必须向 /users 端点发出一个请求,然后为每个用户命中 /users/<user-id>/followers 端点。
2.3 Rapid Product Iterations on the Frontend
REST API 的常见模式是根据应用程序内部的视图来构造端点。这很方便,因为它允许客户端通过简单地访问相应的端点来获取特定视图的所有必需信息。
这种方法的主要缺点是不允许在前端进行快速迭代。每次对 UI 进行更改时,现在都可能比以前需要更多(或更少)数据,而这是高风险的。因此,还需要调整后端以解决新数据需求。这会降低生产率,并显着降低将用户反馈整合到产品中的能力。
使用 GraphQL,可以解决此问题。由于 GraphQL 具有灵活的特性,因此无需在服务器上进行任何额外工作即可在客户端进行更改。由于客户可以指定确切的数据要求,因此当前端的设计和数据需求发生变化时,无需后端工程师进行调整。
2.4 Insightful Analytics on the Backend
GraphQL 可以让您对后端请求的数据有更深入的了解。由于每个客户都准确指定了感兴趣的信息,因此可以深入了解如何使用可用数据。例如,这可以帮助改进 API 并弃用任何客户端不再请求的特定字段。
使用 GraphQL,您还可以对服务器处理的请求进行低层次的性能监视。GraphQL 使用解析器(resolver)功能的概念来收集客户端请求的数据。对这些解析器的性能进行测量和测量,可以提供有关系统瓶颈的关键见解。
2.5 Benefits of a Schema & Type System
GraphQL 使用强类型系统定义 API 的功能。使用 GraphQL 架构定义语言(SDL)在架构中写下 API 中公开的所有类型。此架构充当客户端和服务器之间的协定,以定义客户端如何访问数据。
一旦定义了架构,前端和后端的团队就可以进行工作,而无需进一步的沟通,因为他们俩都知道通过网络发送的数据的确定结构。
前端团队可以通过模拟所需的数据结构轻松地测试其应用程序。服务器准备就绪后,就可以「Flip the switch」,以使客户端应用程序从实际的 API 加载数据。
3. Core Concepts
3.1 The Schema Definition Language (SDL)
使用 SDL 来定义类型。
type Post {
title: String!
author: Person!
}
type Person {
name: String!
age: Int!
posts: [Post!]!
}3.2 Fetching Data with Queries
使用 REST API 时,将从特定端点加载数据。每个端点都有一个明确定义的返回信息结构。这意味着客户端的数据要求已在其连接的URL中有效编码。
GraphQL 中采用的方法是完全不同的。GraphQL API 并不具有返回固定数据结构的多个端点,而是通常仅公开一个端点。之所以可行,是因为返回的数据的结构不是固定的。相反,它完全灵活,可以让客户确定实际需要什么数据。
但是,这也意味着客户端需要向服务器发送更多信息以表达其数据需求,此信息称为 query。
3.2.1 Basic Queries
此查询中的 allPersons field 称为查询的 root field。root field 之后的所有内容都称为 query 的 payload。此外,GraphQL 的主要优点之一是它允许自然查询嵌套信息。例如,如果您想加载一个人撰写的所有帖子,则可以简单地按照类型的结构来请求以下信息。
{
allPersons {
name
age
posts {
title
}
}
}3.2.2 Queries with Arguments
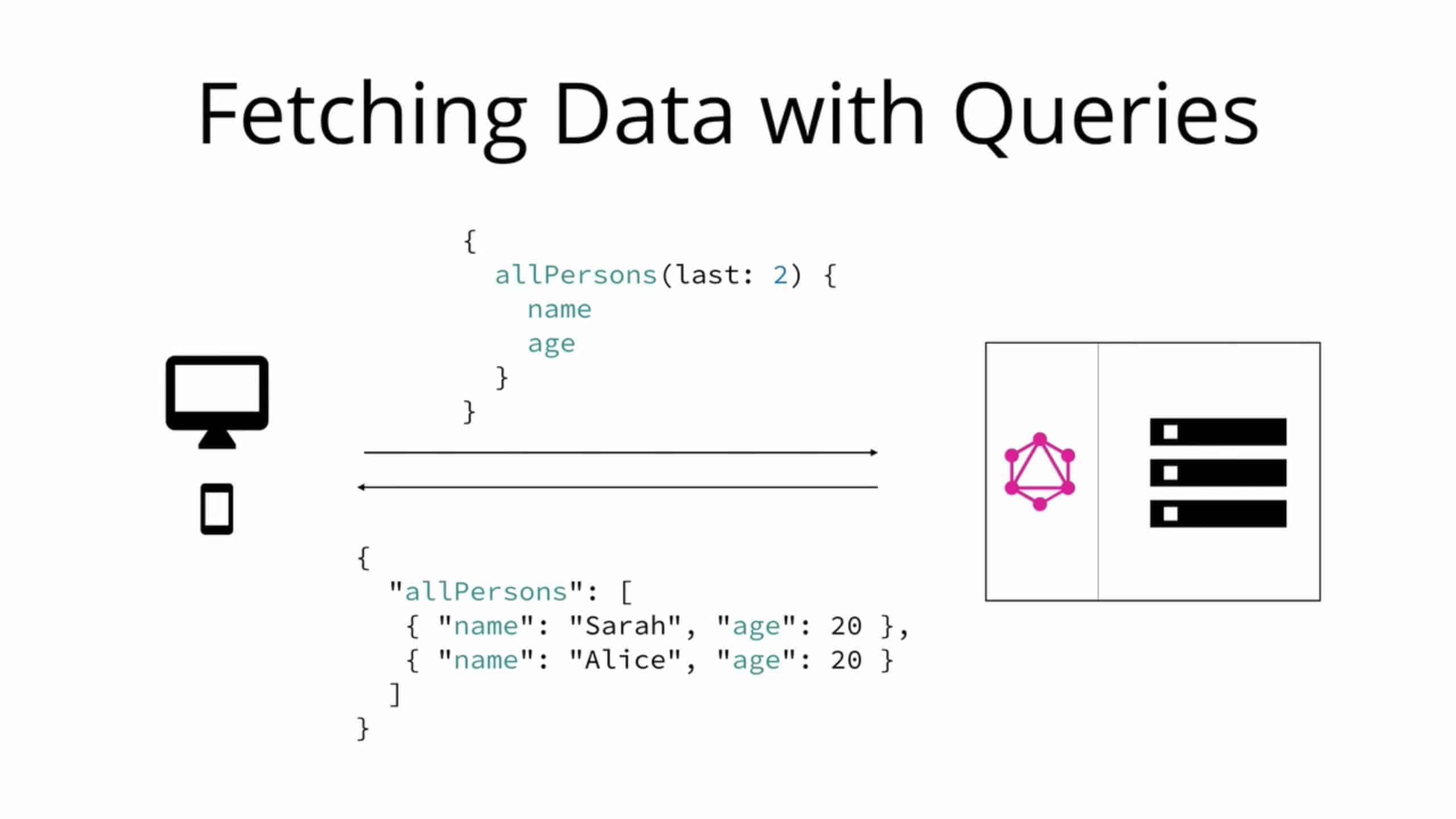
在 GraphQL 中,如果在 schema 中指定,则每个 field 可以包含零个或多个参数。例如,allPersons field 可以具有 last 参数,以仅返回特定数目的人员。相应的查询如下所示。
{
allPersons(last: 2) {
name
}
}
3.3 Writing Data with Mutations
除了从服务器请求信息之外,大多数应用程序还需要某种方式来更改当前存储在后端中的数据。使用 GraphQL,可以使用所谓的 mutation 来进行这些更改。通常存在三种 mutation:增删改。
Mutation 遵循与 query 相同的语法结构,但他们需要以 mutation 关键字开头。这是一个创建 Person 的例子。
mutation {
createPerson(name: "Charles", age: 22) {
id
name
age
}
}3.4 Realtime Updates with Subscriptions
当今许多应用程序的另一个重要要求是与服务器建立实时连接,以便立即了解重要事件。对于此用例,GraphQL 提供了订阅的概念。

客户端订阅事件时,它将启动并保持与服务器的稳定连接。每当实际上发生该特定事件时,服务器就会将相应的数据推送到客户端。与遵循典型的“请求-响应-周期”的 query 和 mutation 不同,预订表示发送到客户端的数据流。
Subscription 使用与 query 和 mutation 相同的语法编写。这是一个示例,其中我们订阅了有关 Person 类型发生的事件。
subscription {
newPerson {
name
age
}
}3.5 Defining a Schema
现在,您已经对 query,mutation 和 subscription 有了基本的了解,下面将它们放在一起,并学习如何编写 schema 以执行到目前为止所看到的示例。
使用 GraphQL API 时,schema 是最重要的概念之一。它指定 API 的功能,并定义客户端如何请求数据。通常将其视为服务器与客户端之间的合同。
总体来说,schema 只是 GraphQL 类型的集合。但是,在为 API 编写架构时,有一些特殊的根类型,如下所示。
type Query { ... }
type Mutation { ... }
type Subscription { ... }这些 query,mutation 和 subscription 是客户端发送请求的入口点(entry point)。为了启用我们之前看到的 allPersons 查询,必须将 Query 类型编写如下。
type Query {
allPersons: [Person!]!
}类似地可以写出 mutation 和 subscription 的类型定义。最终,整个 schema 可能会像下面这样。
type Query {
allPersons(last: Int): [Person!]!
}
type Mutation {
createPerson(name: String!, age: Int!): Person!
}
type Subscription {
newPerson: Person!
}
type Person {
name: String!
age: Int!
posts: [Post!]!
}
type Post {
title: String!
author: Person!
}4. Big Picture (Architecture)
GraphQL 仅作为规范 specification 发布。这意味着 GraphQL 实际上不过是一个冗长的文档,详细描述了 GraphQL 服务器的行为。
4.1 Use Cases
在本节中,我们将带您了解三种包括 GraphQL 服务器的不同架构。
- 连接数据库的 GraphQL 服务器;
- 通过单个 GraphQL API 集成许多第三方或旧系统的 GraphQL 服务器;
- 可以通过相同的 GraphQL API 访问连接的数据库和第三方或旧系统的混合方法。
这三种架构都代表了GraphQL的主要用例,并展示了使用它时的灵活性。
4.1.1. GraphQL server with a connected database
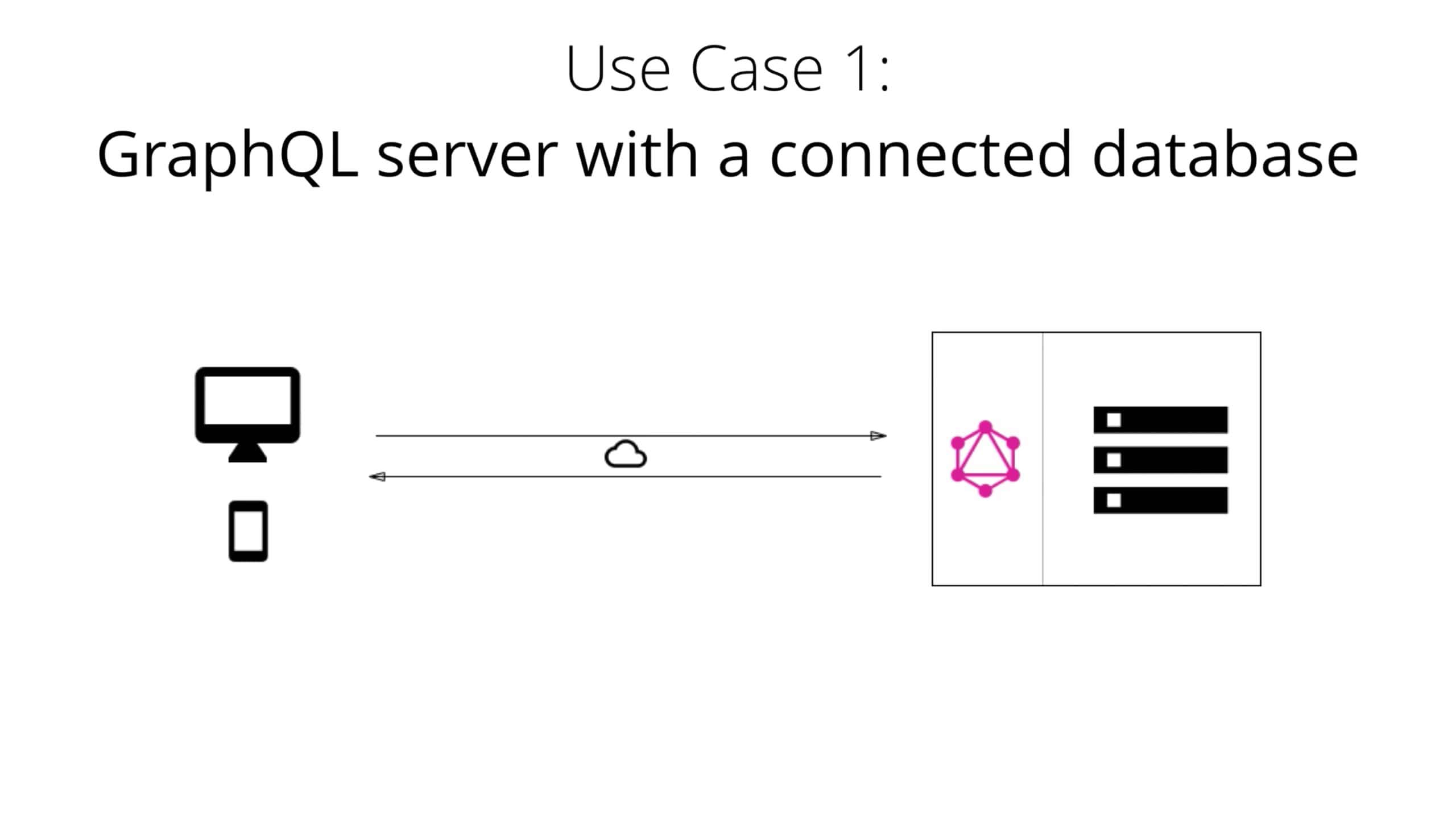
对于新建项目,这种架构将是最常见的。在安装程序中,您具有一个实现 GraphQL 规范的单个(Web)服务器。当 query 到达 GraphQL 服务器时,该服务器读取 query 的 payload 并从数据库中获取所需的信息。这称为 resolving the query。然后,它按照官方规范中的描述构造响应对象,并将其返回给客户端。
请务必注意,GraphQL 实际上与传输层无关。这意味着它可以与任何可用的网络协议一起使用。因此,有可能实现基于 TCP、WebSockets 等的 GraphQL 服务器。
GraphQL 也不关心数据库或用于存储数据的格式。您可以使用 SQL 数据库(例如 AWS Aurora)或 NoSQL 数据库(例如 MongoDB)。
4.1.2. GraphQL layer that integrates existing systems
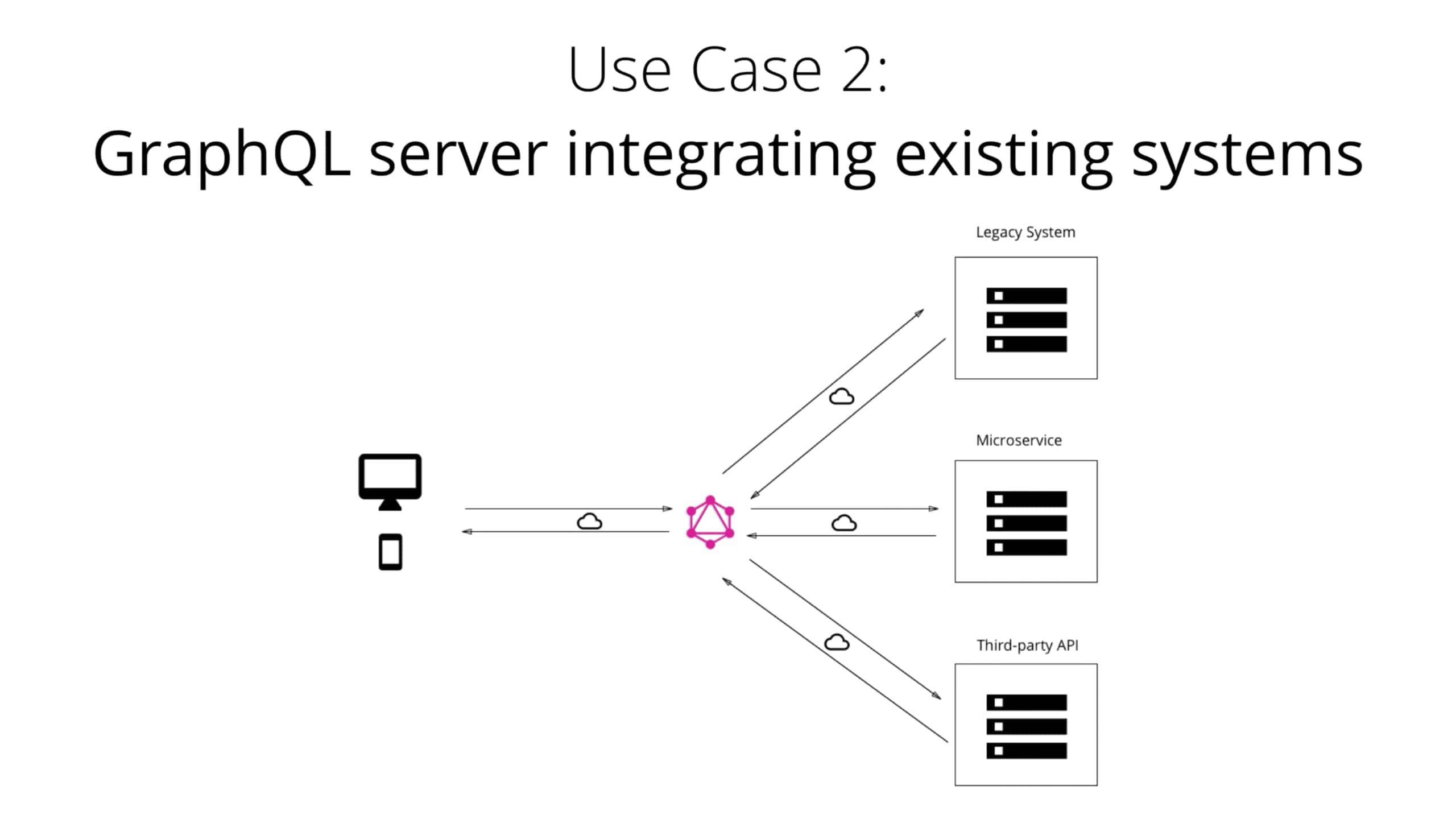
GraphQL 的另一个主要用例是在通过单个一致的 GraphQL API 集成多个现有系统。对于拥有传统基础架构和许多不同 API 的公司而言,这尤其引人注目,这些公司已经发展了多年,现在却承担了很高的维护负担。这些遗留系统的一个主要问题是,它们实际上使当前构建一个需要访问多个系统的创新产品成为不可能。
在这种情况下,可以使用 GraphQL 统一这些现有系统,并将它们的复杂性隐藏在一个不错的 GraphQL API 后面。这样,可以开发新的客户端应用程序,这些应用程序仅与 GraphQL 服务器对话即可获取所需的数据。然后,GraphQL 服务器负责从现有系统中获取数据并将其打包为 GraphQL 响应格式。
就像在上述 GraphQL 服务器不关心所使用的数据库类型的体系结构中一样,这次它不关心需要获取 resolve a query 所需数据的数据源(数据库、web 服务、第三方 API 等等)。
4.1.3. Hybrid approach with connected database and integration of existing system
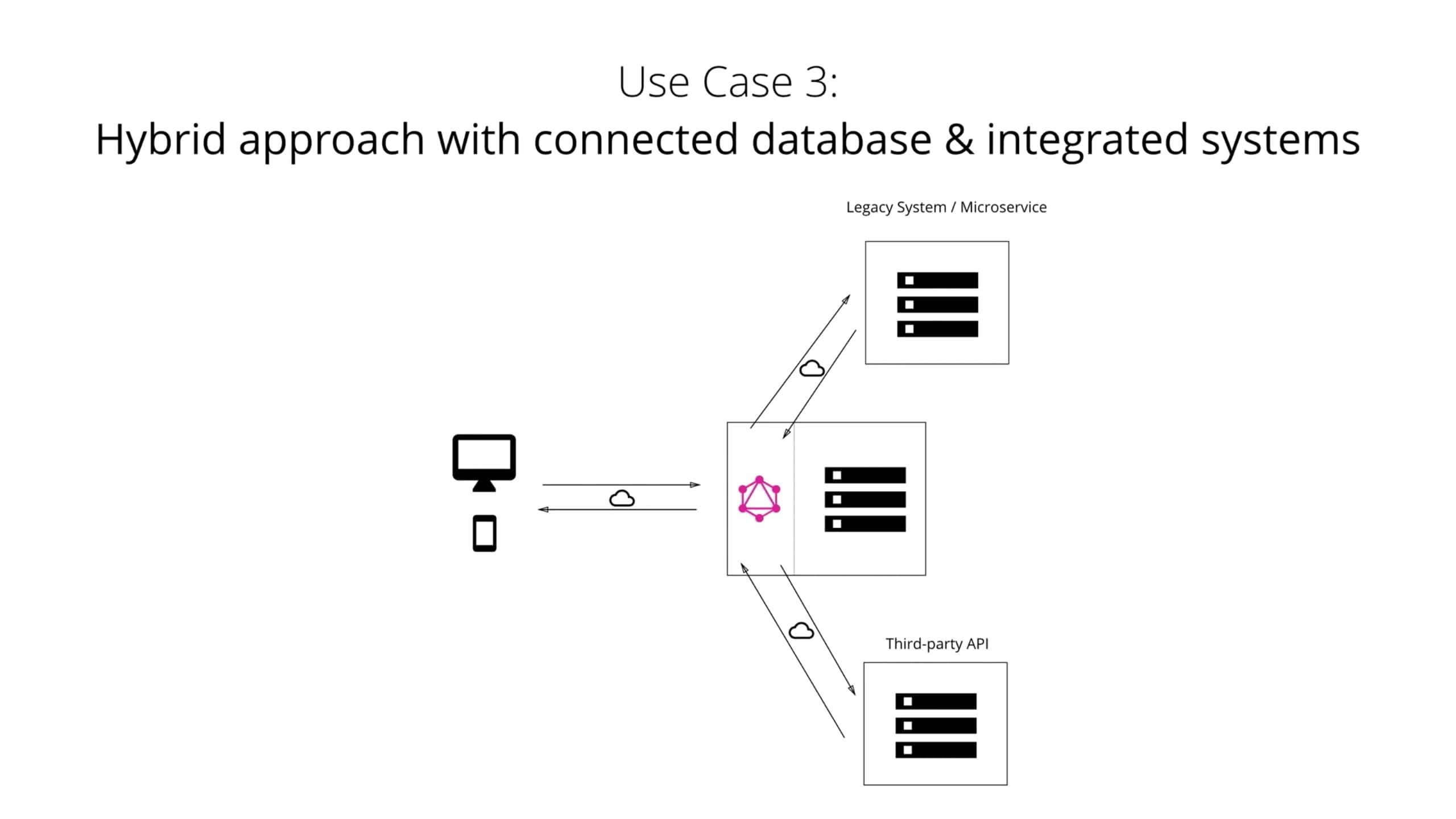
最后,可以将两种方法结合起来,构建一个具有连接数据库但仍可与旧系统或第三方系统通信的 GraphQL 服务器。
服务器收到 query 后,它将解析它,并从连接的数据库或某些集成的 API 中检索所需的数据。
4.2 Resolver Functions
但是我们如何通过 GraphQL 获得这种灵活性? 如何适应这些非常不同类型的用例呢?
正如您在上一章中了解到的那样,GraphQL query 或 mutation 的 payload 由一组 fields 组成。在 GraphQL 服务器的实现中,这些 fields 中的每个 field 实际上对应一个称为「resolver」的函数。Resolver function 的唯一目的就是获取其 field 的数据。
服务器收到 query 后,它将调用 query payload 中指定的 fields 的所有函数。因此,它解析了 query,并且能够为每个 field 获取正确的数据。一旦所有 resolver 返回,服务器将以 query 描述的格式打包数据,并将其发送回客户端。
4.3 GraphQL Client Libraries
GraphQL 特别适合前端开发人员,因为它完全消除了 REST API 遇到的许多不便和缺点,例如过度获取(Overfetching)和获取补助(Underfetching)。复杂性被推到了服务器端,让服务器中功能强大的机器来出来这些繁重的计算工作。客户端不必知道其获取的数据实际来自何处,并且可以使用单个、一致且灵活的 API。
让我们考虑一下 GraphQL 所带来的主要变化,即从一种命令式(Imperative)的数据获取方法转变为一种纯粹的声明式(Declarative)方法。从 REST API 提取数据时,大多数应用程序将必须执行以下步骤。
- 构造并发送 HTTP 请求(例如,使用 JavaScript 中的
fetch); - 接收并解析服务器响应;
- 本地存储数据(存储在内存中或持久存储);
- 在用户界面中显示数据。
而使用理想的声明式数据获取方法,客户最多只需要做以下两个步骤。
- 描述数据要求;
- 在 UI 中显示数据。
所有较低层级的网络任务以及存储数据都应被抽象化,并且数据依赖性的声明应成为主要部分。
这正是 GraphQL 客户端库(例如 Relay 或 Apollo)将使您能够执行的操作。它们提供了一种抽象,您需要能够专注于应用程序的重要部分,而不必处理基础结构的重复实现。